地址。
1. .ckpt文件(CheckPoint) 和 .safetensors文件
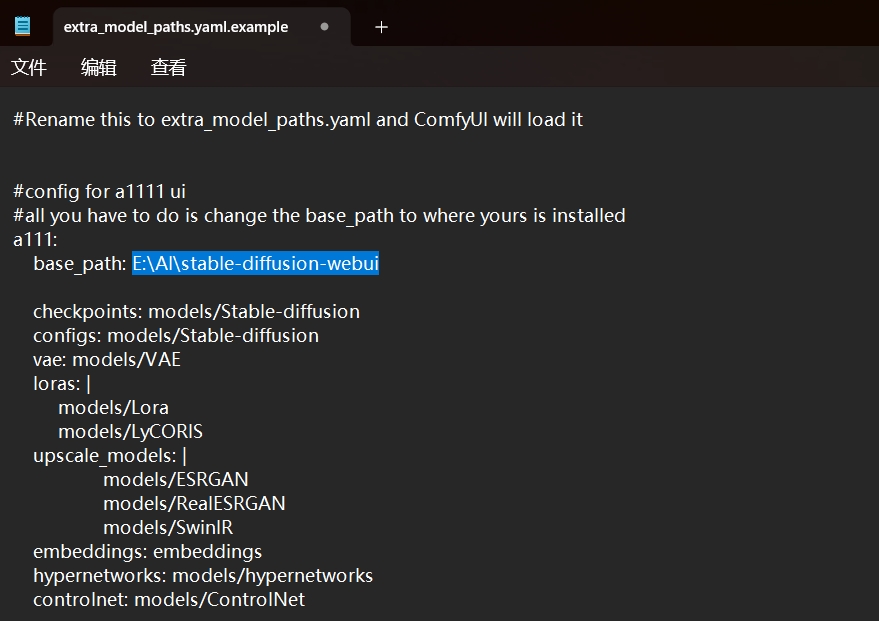
都是用来保存模型权重和参数的文件。模型文件的放置位置:\stable-diffusion-webui\models\Stable-diffusion。
.ckpt 文件是用 pickle 序列化的,可能包含恶意代码。
.safetensors 文件是用 numpy 保存的,这只包含张量数据,没有任何代码,加载 .safetensors 文件更安全和快速。
如今模型文件基本都是.safetensors。
将 .ckpt 文件转换为 .safetensors 文件,你需要先加载 .ckpt 文件中的数据,然后用 numpy 保存为 .safetensors 文件。
模型文件的名称,组成词有不同的含义,如一个模型文件为“v1-5-pruned-emaonly.safetensors”,则:
- pruned是一种剪枝技术,可以减少模型体积,提高运行速度。
- emaonly是一种指定模型文件只包含指数移动平均权重(EMA)的标识。可以降低显存占用。
2. .vae.pt文件
VAE最主要影响画面的色彩质感,所以可以理解成为调色滤镜。
放置位置:\stable-diffusion-webui\models\VAE
使用方法::Settings → Stable Diffusion → SD VAE,选择所需要的VAE。
用来保存变分自编码器(VAE)的权重和参数的文件,VAE 是一种生成模型,可以用来对图像进行编码和解码。VAE 的为 Stable-diffusion 的模型提供:
- 低维的隐空间,可以在这个空间中控制图像的风格和特征。
- 初始化的图像,可以在这个图像的基础上进行细化和改进。
- 颜色校正的功能,可以让生成的图像更加鲜艳或者柔和。
很多模型本身就包含有VAE,不用额外加载。也有适合于多种模型的VAE。
如果模型有VAE文件,最好要加载VAE文件。
3. embeddings
嵌入式向量,一般都用于广泛、容错率高的概念和含义集合。可对于具体的形象和概念,Lora表现更出色。
放置位置:stable-diffusion-webui\embeddings
使用方法:按模型说明输入触发词即可。
embeddings模型是一种用于生成图片的语言理解组件,接受文本提示并产生token embeddings。
embeddings模型可以与编码器和解码器配合使用,通过余弦距离比较编码后的embeddings和目标图片的相似性,从而优化生成图片的质量。
embeddings模型有多种不同的训练方法,例如Textual Inversion、Hypernetwork、Dreambooth 和 LoRA,它们各有优劣和适用场景。
4.LoRA
向AI传递、描述一个准确、具体清晰的形象或者概念。要强化某个形象或者概念的时候,可以多个Lora在一起混合使用。
放置位置:stable-diffusion-webui\models\Lora
使用方法:以<lora:triggerWord:0.8>触发,小数部分表示权重。lora模型说明里或许会有各种各样的触发词,照着说明使用即可。
LoRA是一种用于大语言模型的低秩逼近(Low-Rank Approximation)技术,可以减少参数量和计算量,提高训练效率和生成质量。
LoRA也可以用于Stable-diffusion中的交叉关注层(cross-attention layers),从而改善用文字生成图片的效果。
LoRA模型的个头都比较小,常见的都是144MB左右,使用的时候要与精简版(prund)的Stable Diffusion1.5模型配合使用。
5. ControlNet
ControlNet根据一些额外信息控制扩散的生成走向,微调扩散模型,可以有很广泛的应用(例如控制姿势)。地址。注意下载ControlNet模型的时候,还需下载其yaml配置文件。
6. hypernetworks .pt
用于改变图像的整体风格,也就是画风。前很多时候,可以被LoRa和embeddings取代。
放置位置:stable-diffusion-webui\models\hypernetworks
使用方法:设置 => Stable Difusion => 附加网络 => 将超网络(Hypernetwork) 添加到提示词。至此便可以了,不需要手动再输入提示词。
hypernetworks .pt 文件是用来保存超网络(hypernetworks)的权重和参数的,超网络是一种可以生成其他网络权重的网络。超网络的特点是:
- 可以用来对 Stable-diffusion 的模型进行文本反演(textual inversion),即根据自己的图片训练一个小部分的神经网络,然后用这个结果来生成新的图片。
- 可以用来对 Stable-diffusion 的模型进行风格迁移(style transfer),即根据自己的图片或者其他模型生成一个新的权重,然后用这个权重来改变生成图片的风格。